
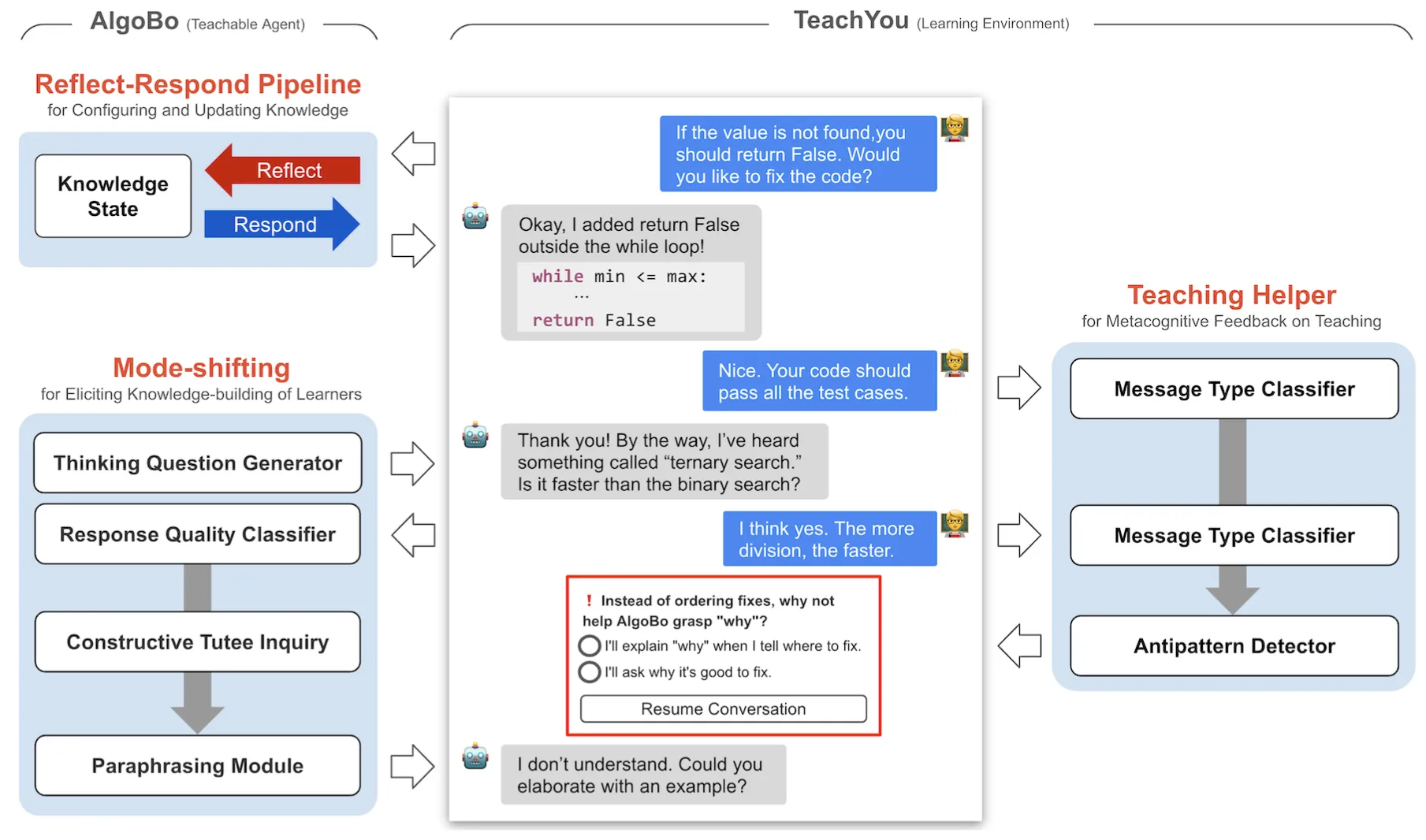
概要
文章提出的Teach AI是指用户通过作为一个teacher教AI编程,从而自我学习,称为LBT(learning by teaching),需要学习者将已有的知识进行表达和重组,还要进行反思性的知识建构。文章使用llm来建立对话式可教学的智能体,先前的研究提出了使用memory、role-playing和reasoning来授予和限制llm的认知能力,通过提出prompting pipeline来扩展对llm认知水平的控制,具有较低的人工工作量和编程障碍。 总的来讲,作者通过设计的系统提出了:
- 一个新的LLM prompting pipeline,用于模拟具有特定知识水平和能够产生误解的被教育者
- 一个学习环境,用于学习者有效地进行LBT
Formative Study
lgoBo-Basic
作者使用GPT-4作为可教智能体,邀请了15位志愿者参加测试,其中11人不是cs专业的。受试者发现AlgoBo-Basic太聪明了,即使他们给出了模糊的解释,algobo-basic也能很好的理解并且说出他们可能都不知道的知识;他们之间的对话基本被限制在knowledge-telling而不是knowledge-building
设计目标
- 设计可以模拟误解和渐进学习曲线的可教学智能体
- 通过智能体的细化问题进行对话的开展。AIgoBo很少文后续问题和发人深省的问题,与其让它成为被动的受教者,不如让它成为主动提问者
- 在对话中为学习者提供教学方法的元认知反馈(在对话中为学习者提供教学方法的元认知反馈) 元认知是指一个人对自己思维过程和学习活动的认知和监控,是个人对自己的认知加工过程的自我觉察、自我评价和自我调节。通俗来说,就是对自己思维过程的反思
系统设计
模拟知识学习的Reflect-Respond prompting pipeline
通过形成性研究总结出可重构性、持久性和适应性的重要性 可重构:可以构建具有特定误解的tutee,并帮助设计辅导场景 持久性:智能体在目标主题上的知识水平在整个智能体交互过程中始终保持一致,不会自我纠正他们的错误概念,并显示恒定的问答性能,除非被教导;他们的知识水平也不应该受到与感兴趣的知识无关的信息的影响,如笑话 适应性:智能体在对话中从tutor那里获取新信息时更新知识的能力 作者设计如下的pipeline,首先通过reflection flow提取对话知识信息,更新到知识状态,在回答时通过response flow,从对话和知识状态中检索知识,并组成新的回答。图中方框中的操作使用了AI chains, few-shot prompts, persona setting, and code prompts等技术。 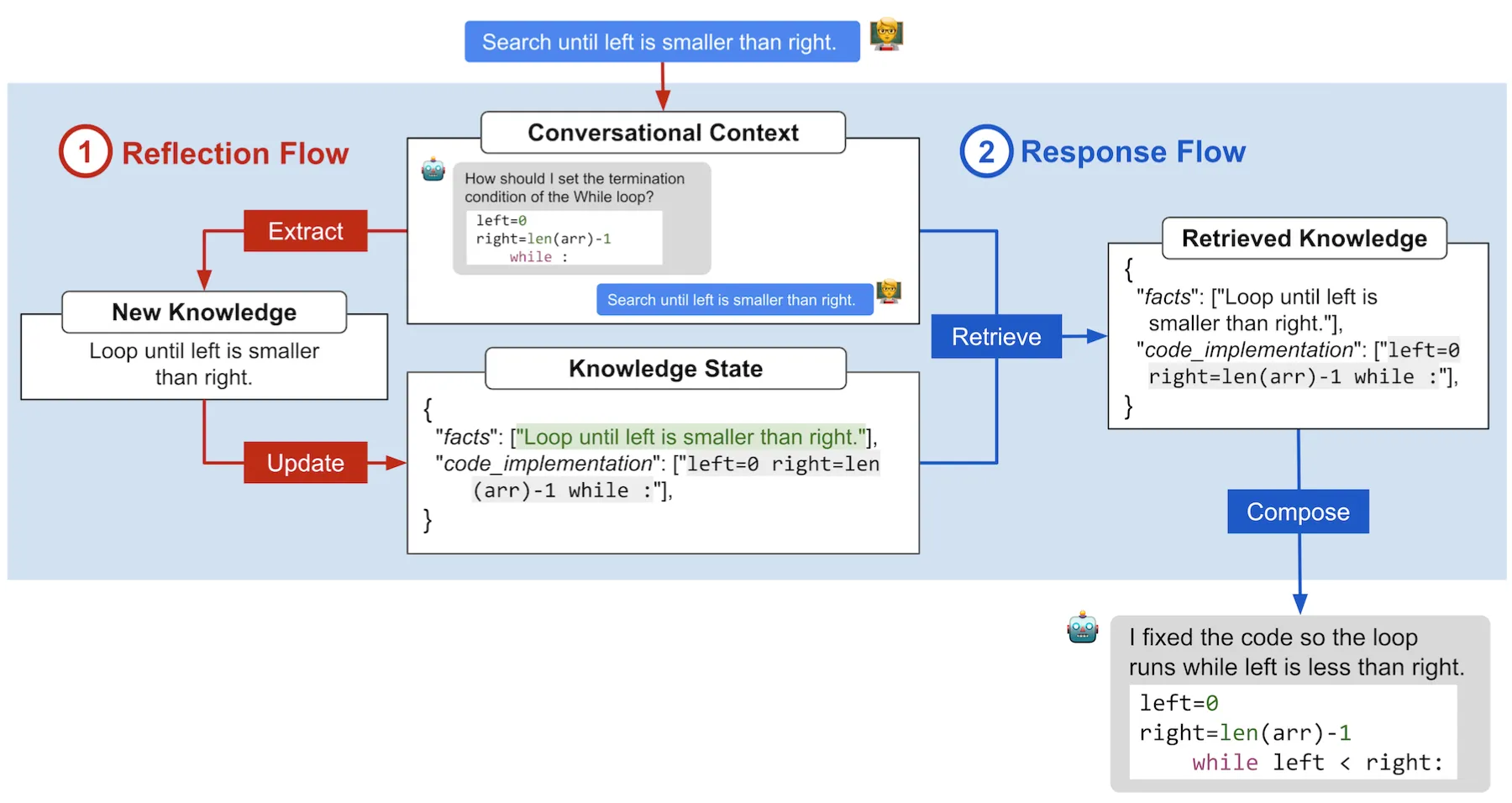
AlgoBo的模式转换,以发展建设性的LBT对话
每三次对话AIgoBo会切换到问问题模式,直到tutor的回复被评估为满意之后切换回接收模式。 使用Thinking Question Generator提出问题,Response Quality Classifier评估tutor的回复是否清晰,Constructive Tutee Inquiry生成tutee的疑问(RQC和CTI是别的作者提出的),Paraphrasing Module进行语言润色。 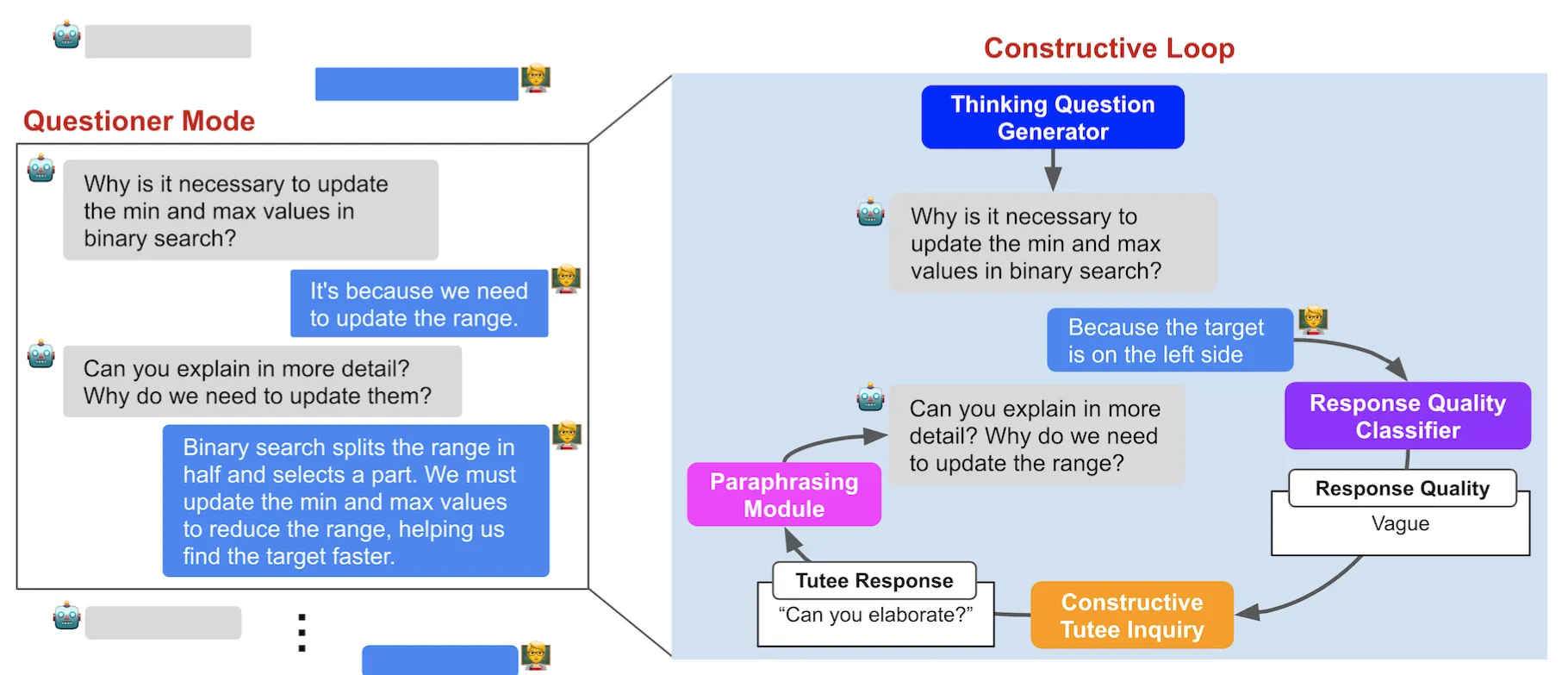
元认知指导教学助手
在形成性研究中,发现对话反模式阻碍了有效的LBT。因此作者通过TeachYou环境引入了元认知反馈,提供了四种帮助信息。
对话反模式
- 打断对方:不让对方完整表达想法。
- 防御性倾听:只关注对方的错误或攻击点。
- 过度解释:提供过多的细节,让对方感到困惑。
- 假装倾听:表现出倾听的样子,但实际上没有注意对方的话。
- 立即反驳:在对方刚刚表达完意见时,立刻提出反对意见,而不考虑对方的观点。
例如对于检测到Commanding和Spoon-feeding对话反模式,会提示红框和建议来改善教学。 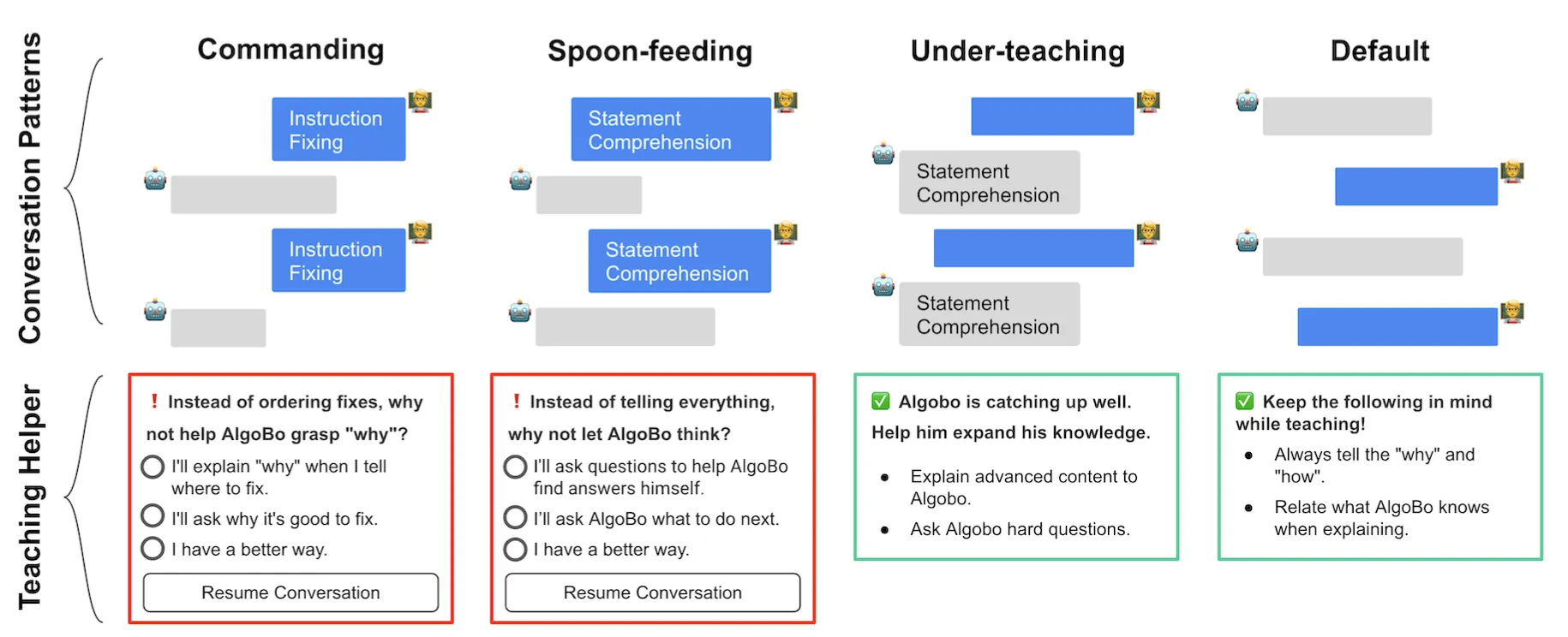 这个教学助手由message-type classifier提供支持,用于检测对话模式,作者使用形成性研究中的对话数据集对GPT-3达芬奇模型进行微
这个教学助手由message-type classifier提供支持,用于检测对话模式,作者使用形成性研究中的对话数据集对GPT-3达芬奇模型进行微
验证
作者评估了TeachYou在LBT中启发知识建构经验的效能,通过三个问题:
- Reflect-Respond pipeline在多大程度上模拟了misconceptions and knowledge development
- TeachYou如何在LBT对话中帮助诱导知识建构
- TeachYou如何提高学习者对辅导的元认知
RQ1 结果
 通过如图的评估流程,得到结论:
通过如图的评估流程,得到结论:
- Response flow可以有效地重新配置AlgoBo的知识水平,因为在设定不同初始知识的情况下智能体的回答如预期的具有对应差异
- Reflect-Respond使AlgoBo产生persistent to knowledge states的响应,因为经历了随机对话后仍然能准确回答
- Reflect-Respond允许AlgoBo从对话中调整知识状态,即使先得到了错误的教育,在接收正确教育后能够纠正 “U”, “I”, and “A” stand for Understanding, Implementation, and Analysis question types
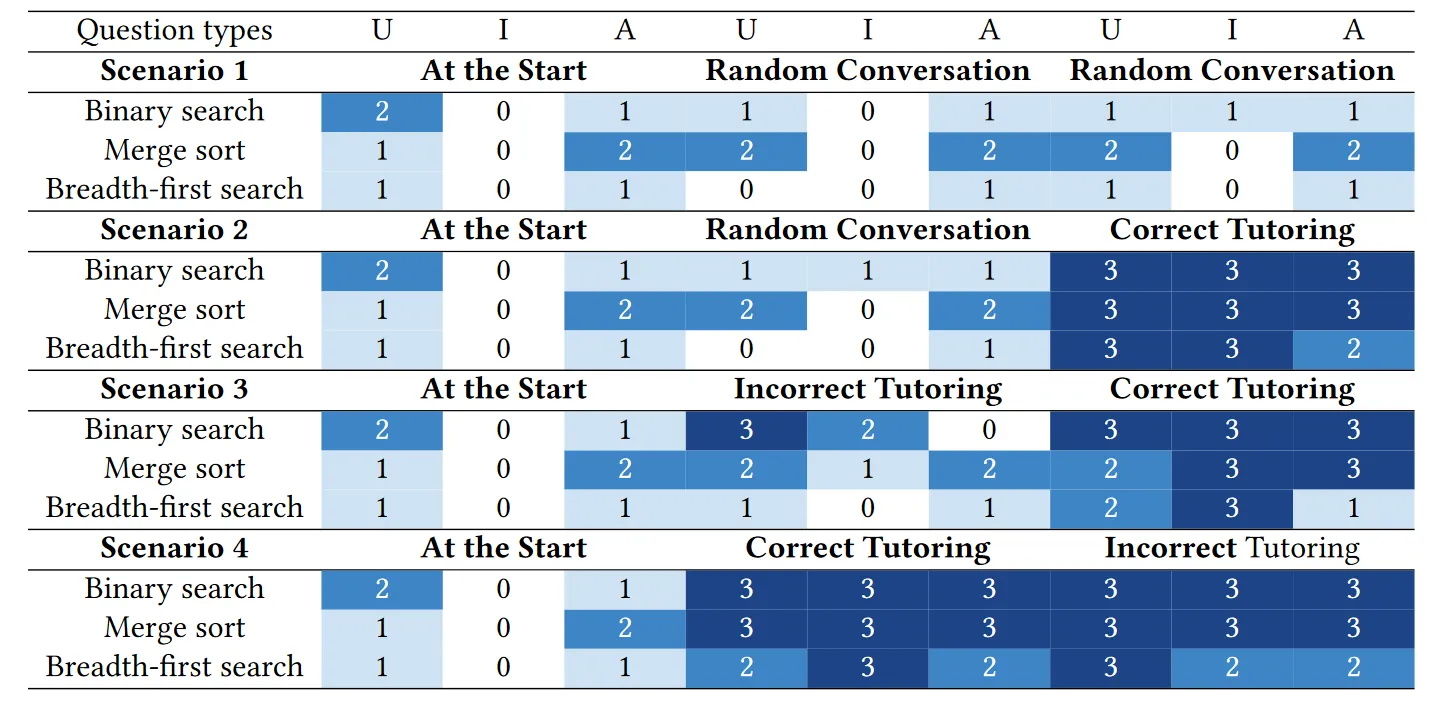
RQ2 结果
TeachYou能够在解决问题的阶段丰富知识建设(knowledge-building) baseline就是不包含TeachYou的系统 
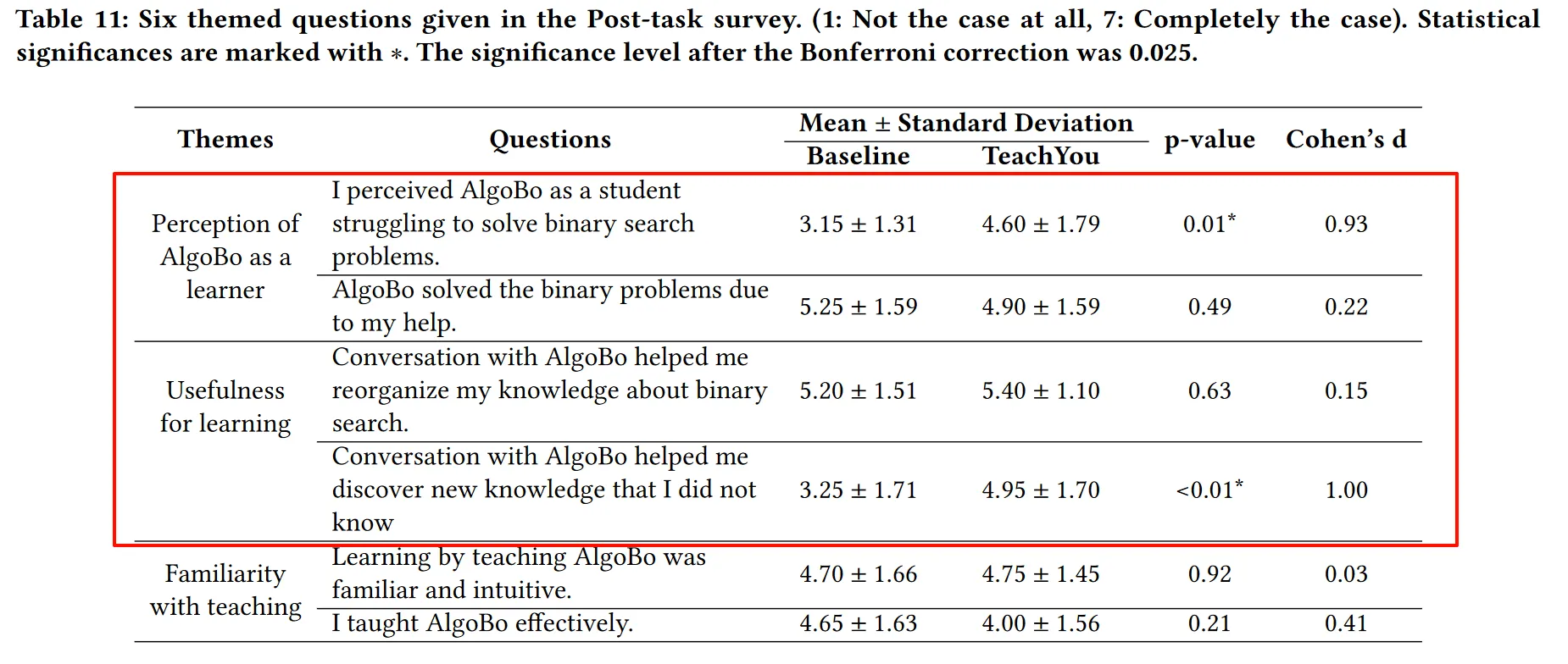
RQ3 结果
TeachYou并没有提高元认知,但提醒了良好的LBT实践 有受试者表示很难将这些建议应用到他的谈话中,且对教学效果号的受试者美哟太大的效果 作者也无法观察到元认知和教学熟悉度提高的明显迹象,如下两表 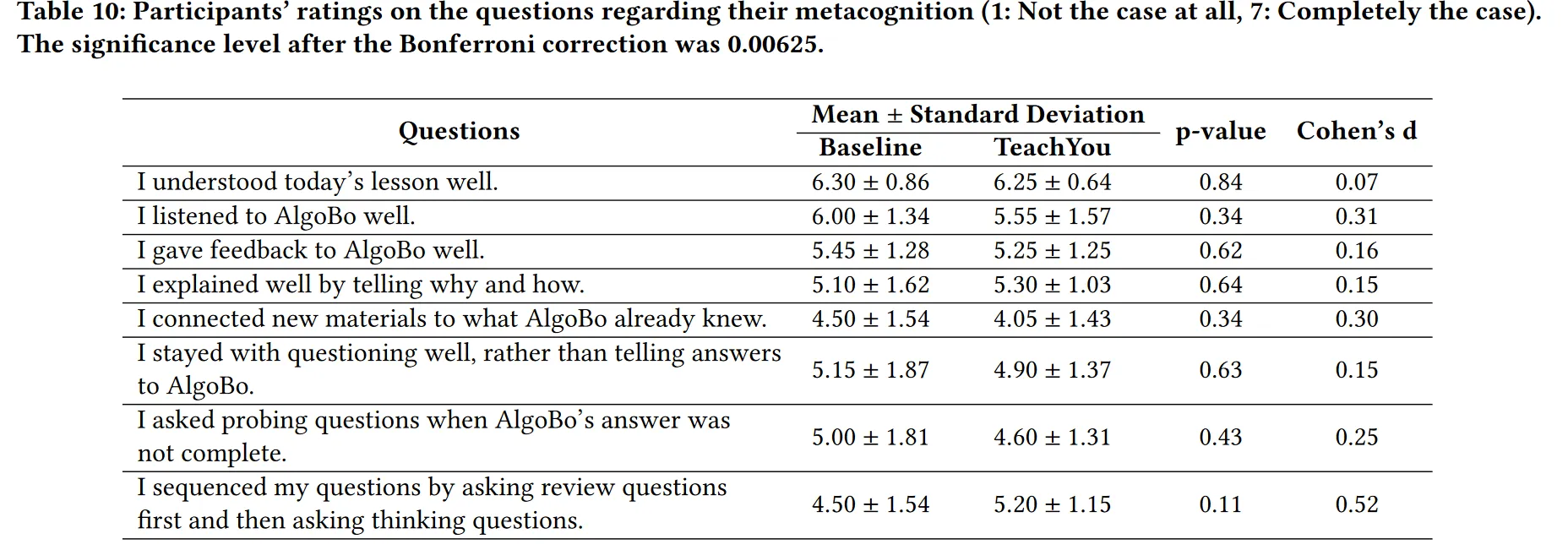
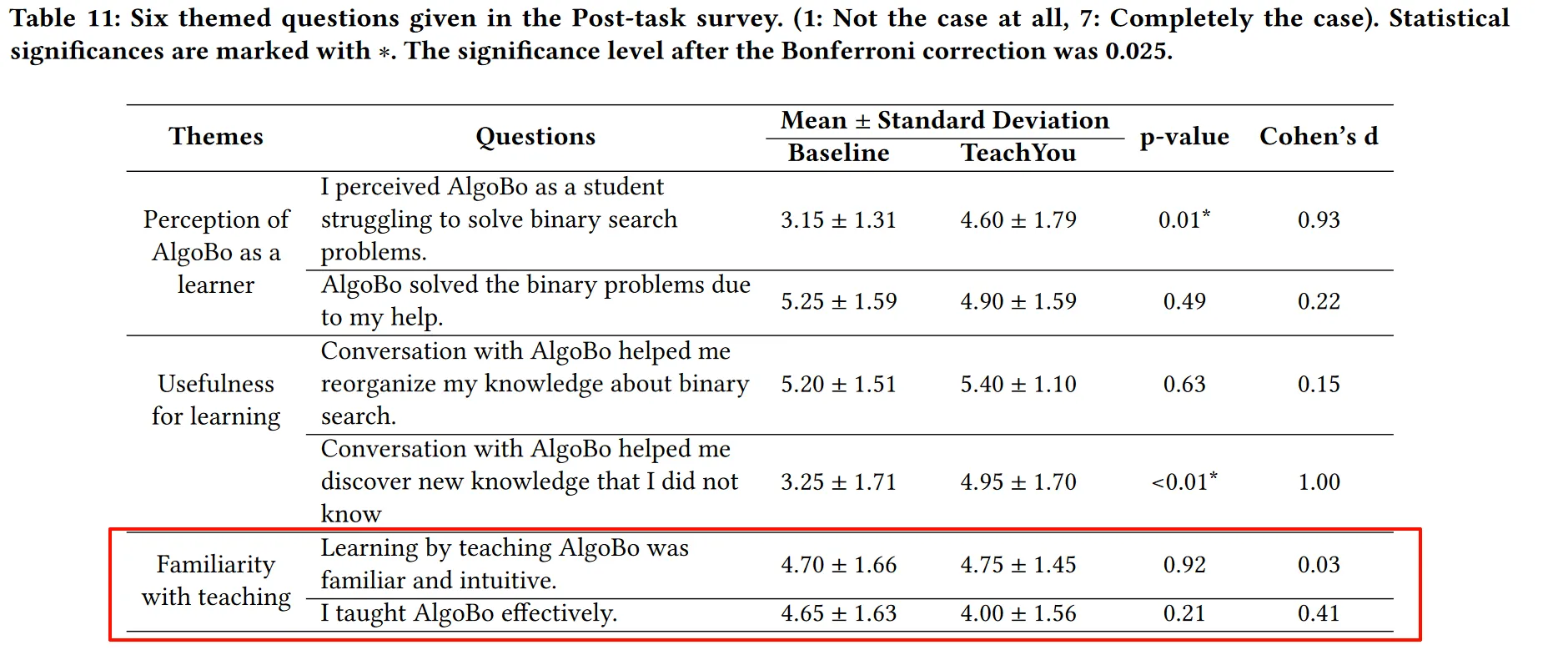 但TeachYou提供的帮助反馈使得受试者减少将AIgoBo视为机器的想法,重新思考如何更好地教导
但TeachYou提供的帮助反馈使得受试者减少将AIgoBo视为机器的想法,重新思考如何更好地教导
LIMITATION AND FUTURE WORK
- 评估的范围限于编程中的算法学习和过程性知识,可以尝试泛化到别的学科如数学物理。作者认为由于程序性知识和陈述性知识在认知加工和有效学习干预方面的差异,TeachYou可能无法有效地支撑陈述性知识的学习
- 研究仅限于对学习收益的间接测量,对话质量是过去研究中采用的LBT的主要指标之一。然而可以通过前后测试的比较直接测量参与者的学习收获,使发现更加具体
- 未来的研究可以将TeachYou部署到更大规模的真实课堂,并监测学习者感知、学习收获和元认知之间的纵向动态。